
It’s the best of times because businesses today have access to mind-blowing new big data technologies that barely existed a decade ago. Alongside traditional data management solutions like NoSQL databases, organizations can now benefit from technologies like Kafka and Spark. They can also take advantage of highly scalable, dirt-cheap data storage services, such as AWS S3. And they can connect these various data sources to sophisticated analytics tools that drive informed, nuanced decision-making.
On the other hand, we’re living in the worst of times because the hurdles to accessing modern big data technology are higher than ever – or they have been, until recently. Actually taking advantage of the various data management, processing and analytics tools like the ones described above has traditionally required extensive coding. And because most data analysts are not coders, they have had to depend on overstretched development teams to build pipelines for them – a process that can take months, which significantly slows down the rate at which organizations can make decisions based on their data.
Fortunately, a better world is possible. Using no-code visual Extract, Transform, Load (ETL) technology, businesses can create and execute the data pipelines they need in hours instead of months, without burdening their development teams.
Let us elaborate by explaining how the barriers to using big data technology have become so large, and how no-code, visual ETL solutions can finally break them down.
How we got here: The rise of NoSQL, ETL and Spark
Businesses have long been managing large amounts of data. Traditionally, their primary data management tool was SQL databases, which store data in rigid, preordered ways.
However, starting in the late 2000s, something of a revolution took place in the big data space as new types of data storage technologies emerged. In addition to cloud-based object storage services, a variety of NoSQL databases arose. There are multiple types of NoSQL databases, and they all work in somewhat different ways. In general, however, NoSQL provides businesses with a flexible, scalable means of storing data. It’s less rigid than SQL databases, which force data into inflexible structures that can make it hard to accommodate varying types of data at a large scale.
However, there is a big downside of NoSQL databases: Their complexity – combined with the fact that each NoSQL implementation has its own query language – means that there is a steep learning curve. It’s very hard to find developers who know how to write good queries for a particular NoSQL database. It’s even harder to find ones who can join data across NoSQL databases.
Partly for that reason, the late 2000s also witnessed the embrace by many businesses of a new approach to data processing. Rather than trying to query data stored in NoSQL databases directly, organizations began using ETL architectures, which simplify the process of processing data from multiple databases at scale. ETL had originally been feasible only for large companies (like Google, which developed an ETL solution called MapReduce, whose functionality later became an important part of open source Hadoop) that could develop ETL platforms in-house. But the appearance of platforms like Apache Spark, which debuted as an open source project in 2009, placed ETL within reach of the masses.
Spark isn’t the only ETL solution available today, but it has become the go-to ETL platform for a majority of use cases. That’s partly due to its open source nature, but also to advantages like Spark’s support for in-memory data processing (which greatly speeds data pipelines by avoiding the bottlenecks caused by traditional disk I/O) and its distributed architecture (which makes Spark ideal for executing pipelines that span multiple data sources on distributed infrastructure).
Code: The barrier to democratized big data
In theory, then, the debut of ETL technologies like Spark made it possible for any business to build flexible, high-performing, highly efficient data pipelines using open source tooling. In theory, they heralded a new, democratic age of big data in which any company could create a data pipeline tailored to its needs.
But there was one problem: Building those pipelines required the ability to write code. Spark still requires code written in Scala, Java, Python, R or Spark SQL (Spark’s homegrown declarative language) to define data pipelines.
This posed a major limitation because most data professionals are not coders. Some can’t write code at all. Those that can are typically most familiar with “simple” languages like Python – which, although it is arguably easier to learn, results in code that is about 100 times less efficient, because it is not compiled before execution.
Thus, the big data revolution fell short in many cases of achieving its full promises. The technologies existed, but they were hard for businesses to use without the help of professional coders to construct pipelines.
The solution: No-code visual Spark ETL
No-code ETL solutions are finally solving this dilemma. No-code ETL makes it possible to define data pipelines using a visual interface, without having to write any code by hand. You can still write and execute custom code if desired, but you can also create complex, custom data pipelines in a totally code-free fashion.
In this way, no-code ETL allows anyone to take full advantage of Spark, NoSQL and other modern big data technologies. At the same time, it reduces the burden faced by development teams. A business’s professional coders no longer have to be distracted by data pipeline development projects; instead, they can focus on other priorities – like writing business applications.
Spark Native ETL – The BigBI approach to visual ETL
There are a few visual ETL solutions on the market currently. Most, however, work only within certain vendor ecosystems or support only certain types of data architectures. Most have some pre big data legacy architecture & features, making it hard to take advantage of specific technologies, like Spark.
We built BigBI to serve as a platform-agnostic, cloud-agnostic, architecture-agnostic visual ETL solution that makes Spark-based data pipelines accessible to everyone. BigBI is the only no-code ETL tool built specifically for Spark that works interactively with the Spark cluster, placing the full power of Spark in the hands of everyone at the organization.
In this way, we’re closing the gap separating big data tooling from big data analysts in order to deliver fully on the democratizing potential of modern data technologies. With BigBI, anyone can create and execute data pipelines with Spark in hours, instead of waiting months on professional coders to write the programs they need. And they can do it regardless of where their data lives – on-premises, in a public cloud, in a private cloud or in a hybrid architecture.
We’re delighted to be part of the movement that is finally placing modern big data technology within easy reach of everyone, and we’re looking forward to continuing to build out our platform with even more features and tools that simplify ETL while simultaneously giving businesses sophisticated control over their ETL pipelines.
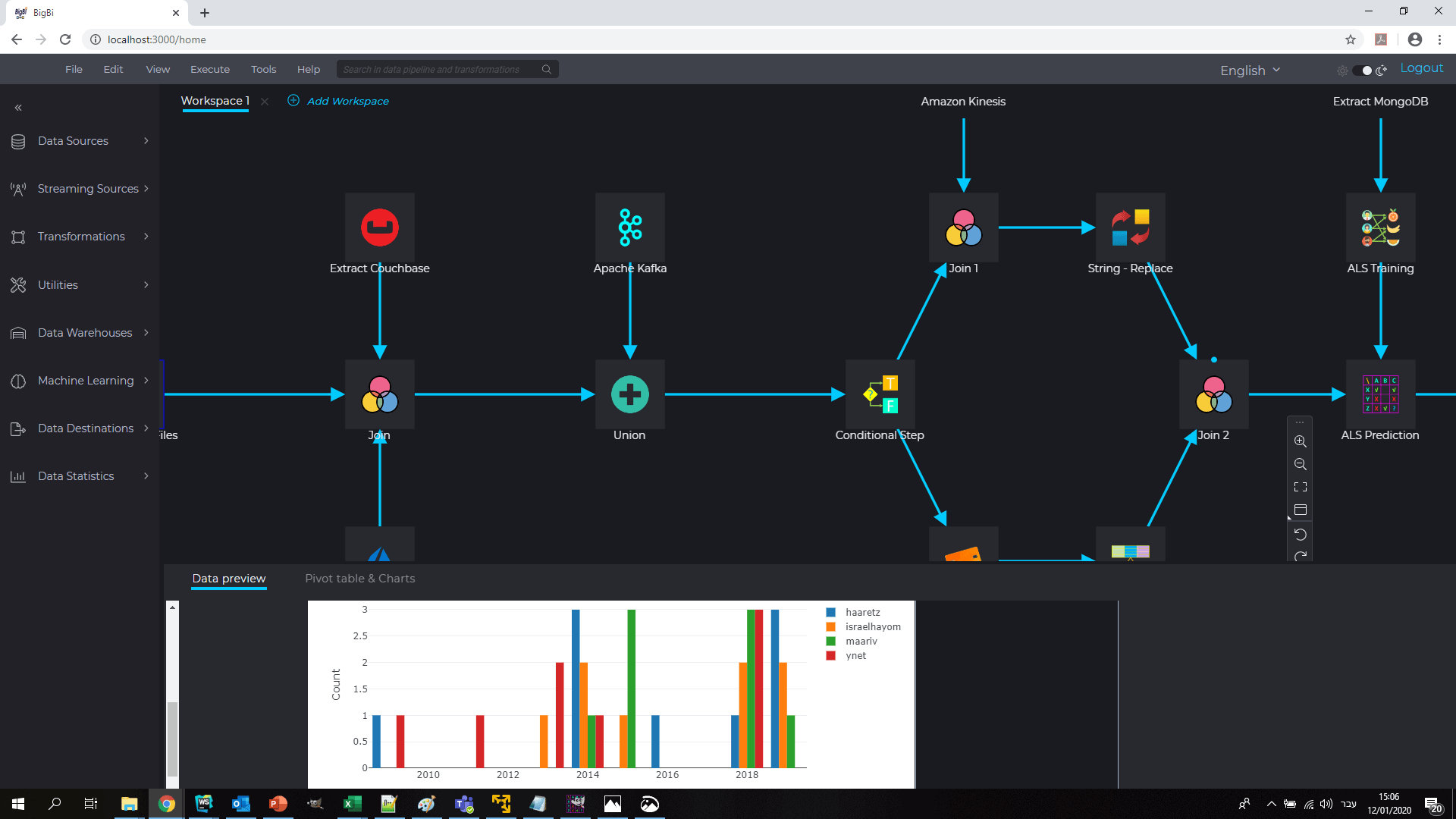
BigBI is Spark Native No-code visual ETL. Developing a new data pipeline is being done through a live connection with a live Spark context, so the user could see data samples after every operator and interactively debug the results with full debug tool sets. Being spark native enables BigBI to support natively spark distributed running as well as full set of Spark features such as integration of streaming with batch, semi-structured & unstructured data, machine learning & graph algorithms.
BigBI really gives the full power of Spark to the hands of the business analyst & data scientist.

