
Whitepapers
Ebook: No-Code Apache Spark Big Data Pipelines for BI Analysts & Data Scientists
The challenge of big data is not going away and the complexity of data is expected to become even greater – to prevent bottlenecks or

All the power of ![]()
without the <coding>
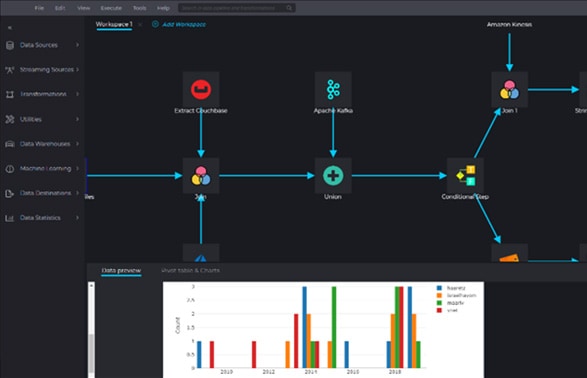
Drag & Drop
Breakpoints + Full
interactive debugging
Examine interactive data samples
from any source & after
each processing stage
export JAR for production









The challenge of big data is not going away and the complexity of data is expected to become even greater – to prevent bottlenecks or
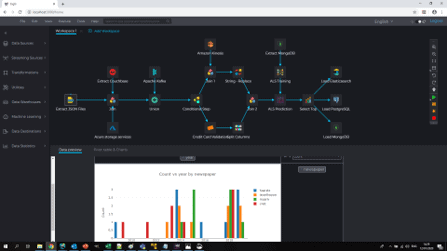
When it comes to big data, this is both the best of times and the worst of times.

Big data is no small data – why BI specialists need to turn away from Legacy ETLs.