For several decades enterprise Business Intelligence (BI) departments have been building visual data pipelines on legacy visual ETL (Extract, Transform, Load) platforms that are the industry-standard when it comes down to enterprise data integration, data preparation, and KPI calculation. BI departments came to appreciate the ease of use and interactivity afforded by visual no-code ETL tools such as Informatica, Microsoft SSIS, IBM DataStage, Pentaho, and Alteryx. BI analysts could build and update their visual data pipelines by themselves within few hours per data pipeline, in visual form, using at most SQL queries or regular expressions, without needing the full software R&D process (including software specification, writing, and debugging code, QA, deployment etc.), which could take weeks or months (in case the relevant developers are free, and the specific mission is righty prioritized for them). With visual ETL tools, BI analysts could focus their knowledge about the enterprise data repositories and needed business KPIs to easily prepare new reports and/or generate new KPIs promptly This dramatically shorter time-to-insight and the breadth of use of the visual ETL tools by analysts in departments throughout the organization enables business departments take business decisions with substantial dollar value, immediately and within the proper department instead of months delay and centralized only.
More recently, however, many BI professionals have been facing increasing issues when attempting to process modern data sets with their visual no-code legacy ETL platforms, Apparently, legacy visual ETL platforms are less adequate for processing big and modern data. Here are some issues reported by clients and prospects we are meeting:
- An industrial digital printing manufacturer had an internet-of-things (IoT) analytics that remotely monitored the health and usage of thousands equipment units at customer premise. This IoT analytics solution has been implemented on a SQL-based infrastructure. They have found that only 80% of their data processes could be completed in each run of the process using their traditional ETL tools. The process performance was so poor that the data would refresh only every 3 days. The manufacturer had to replace some of their key performance indicators (KPIs) with less-accurate, easier to compute metrics because of the excessive computational burden of calculating the original KPIs. Since the company business model is revenue sharing with its customers, the impact on the business was critical.
- A bank needed to have its nightly ETL processes completed by 6 a.m. each business day to feed its critical morning reports. Often these ETL processes were running until 8 or 9 a.m., resulting in delays in readiness of the daily reports and unnecessarily repeating stress on the data operations team.
- A financial institution needed to process Google Analytics 4.0 data and integrate it with a Hive-based enterprise data warehouse as well as many other more exotic data sources. The legacy ETL needed much more time to parse through the data and could not complete the jobs in the required time frames. Some of the data sources were not easily accessible so could not be included in the customer model, resulting in less accurate prediction
What changed? Why were these rock-solid legacy visual ETL platforms failing them?
It wasn’t the tools that changed, it was the data. Specifically: more of these organizations’ data evolved to “big data.”
Big data is not just about size…
Big data (also known as “modern data”) differs from traditional (“small”) data sets, and it’s not just about size. Data that meets one or more of the following “4 Vs” can be considered “big data”:
- Volume: Yes, it starts with Volume. Usually, customers with data that exceeds few Terabytes (not to mention Petabytes) usually need to move to big data architecture. Data complexity should also be looked at as part of counting data volume. Tables with hundreds of columns or millions of rows require big data architecture.
- Velocity: This includes considerations such as:
- How fast is the raw data coming in (measured in transactions per time unit)
- Need for real-time (or near real time) analytics to update dashboards, real time personalized recommendations etc.
- Usage of data streaming architectures such as Apache Kafka to stream raw events (usually in real-time) that needed to be processed for insights with or without integration with more traditional “static” data repositories.
- Variety: Where traditional data was based on structured data repositories such as SQL tables, dozens of new formats are being used to encompass the huge size and complexity in the era of big data, including Semi-structured (NoSQL databases such as MongoDB or Cassandra, JSON files, Elastic search, graph databases) & unstructured data as raw text, audio & video.
- Veracity: The trustworthiness of big data may be harder to determine but is all the more important given the criticality of the decisions being made on its basis.
Here at BigBI, we added a fifth “V”: Artificial intelligence (AI) and machine learning (ML). (We know, there’s no “V” in either of those. Don’t overthink it.) Data that is best processed or analyzed with artificial intelligence algorithms can fall into the big-data category.
Other ways to distinguish big and small data include the following:
| Attribute | Small Data | Big Data |
| Data size | Less than 1 TB | Unlimited, even can be petabytes (PB; 1 PB = 1,000 TB) per time period |
| Data structures | Structured into tables, rows, and columns (for example, relational databases) | Structured, semi-structured (such as JSON, XML), nonstructured (free text, audio, video) |
| Supported data sources | SQL | SQL, NoSQL, file systems |
| ETL operation mode | Batch | Batch, Streaming |
| Velocity (data arrival speed) | Slow | Fast |
| Data quality | High | Varies |
| ML / DL (AI) support | No | Yes, when needed |
| Graph algorithm support | No | Yes, when needed |
| Architecture deployment | Mostly single server | Distributed architecture |
As a rule of thumb, if any two of these characteristics suggest “big data,” it’s safe to assume that it is. Even if the size of the data does not exceed the 1-TB threshold, you may have a big-data problem if your systems are using modern data structures, such as NoSQL or graph databases, or include audio, video, unstructured text, or other nontraditional data types.
The Breakdown of Legacy Visual ETL
The issue is that legacy visual ETL platforms are not a good fit for modern data challenges, such as big-data scalability, modern data paradigms, and AI/ML integration. Legacy ETL tools were never designed for the size and velocity of modern data, and lack the ability to handle modern data analytics, such as graph algorithms.
The examples discussed at the beginning of this article can be explained through this lens:
- Streaming data: static SQL-based ETL works best with data that represents a “snapshot in time,” and not continuously changing. Streaming data–and in particular, streaming data that is produced by a significant amount of IoT sensors at once–can’t be processed this way; in some cases, it must be processed and analyzed in real-time.
- Long-running ETL processes: The volume of data in these examples was simply too large, and the KPI calculations were too computationally burdensome for a single server to handle.
A Step in the Right Direction: Apache Spark

In order to better deal with the growing size, complexity, and volume of their data, organizations are turning to Apache Spark for big data analytics and ETL. Apache Spark is an open-source big-data processing platform that is specifically designed to overcome the limitations of traditional ETL tools.
As a distributed computation processing environment, Spark can take advantage of private cloud, public cloud, and hybrid environments, dividing up the ETL tasks among all of the computing and storage resources that it has access to. As a result, an Apache Spark analytics process can run 100 times faster than the same process run on the previous computing paradigm (Hadoop MapReduce).
But Apache Spark is far more than just a distributed big data analytics paradigm. As the leading open source for big data and machine learning, Apache Spark has built-in libraries to handle all type of semi-structured and unstructured data and the ability to integrate streaming data with static data repositories, such as AI/ML & graph algorithms and many more highly important features for big and modern data analytics.
Is Apache Spark the Solution?
However, although Apache Spark software is by far the best big-data processing platform available, it usually requires architect grade coding skills to build extremely efficient data pipelines. Apache Spark data pipelines can be developed in various programming languages, including Scala, R, Java, and Python. Most data analysts are not skilled in those (or any) languages. Some Data Scientists & analysts know to write in Python or R, which are great for playing with data to craft new algorithms but is much less efficient in building real big data pipelines (Scala is much more efficient as it is a compiled language, enabling many more processing optimizations).
As a result, data professionals must depend on development resources to build efficient big-data pipelines–a process that can take weeks or months for each project.
Apache Spark is better at dealing with big data than legacy visual ETL platforms, but it isn’t visual, nor self-service for non-coders. BI professionals want, and need, a visual solution so that they can do their jobs with the same ease of use and flexibility they enjoyed with their legacy visual ETL tools. In few hours per data pipeline, without the need to wait for a long R&D cycle.
Apache Spark is a crucial enterprise data strategy building block as it is based on open source hence it provides both a hybrid environment (same Spark on both private & public cloud) as well as multi-cloud & cloud agnostic organizations that want to be free to move between cloud vendor environments anytime.
BigBI: Spark-Native Visual ETL
There is a better way: BigBI.
BigBI studio is a no-code, visual Spark native ETL for building and maintaining big-data analytic pipelines. With BigBI, an organization can harness the power of Apache Spark without the need to engage with high-priced development resources and long backlogs of data pipeline coding projects.
Offload Your Legacy ETL with BigBI
Your organization doesn’t have to make the tough tradeoff- either stick with the broken legacy visual ETL or get the performance and feature richness of Apache Spark, with the cost of lengthy R&D cycles.
BigBI provides the only Spark Native visual big data ETL that brings the full power and feature richness of Apache Spark to the hands of any business analyst & data scientist with no need for coding, As BigBI is Spark Native, the analyst gets a highly interactive pipeline development experience where sample data could be visualized after each processing step, expediating pipeline development and generating confidence about how such pipeline works. All data is being shown interactively directly from the Spark cluster.
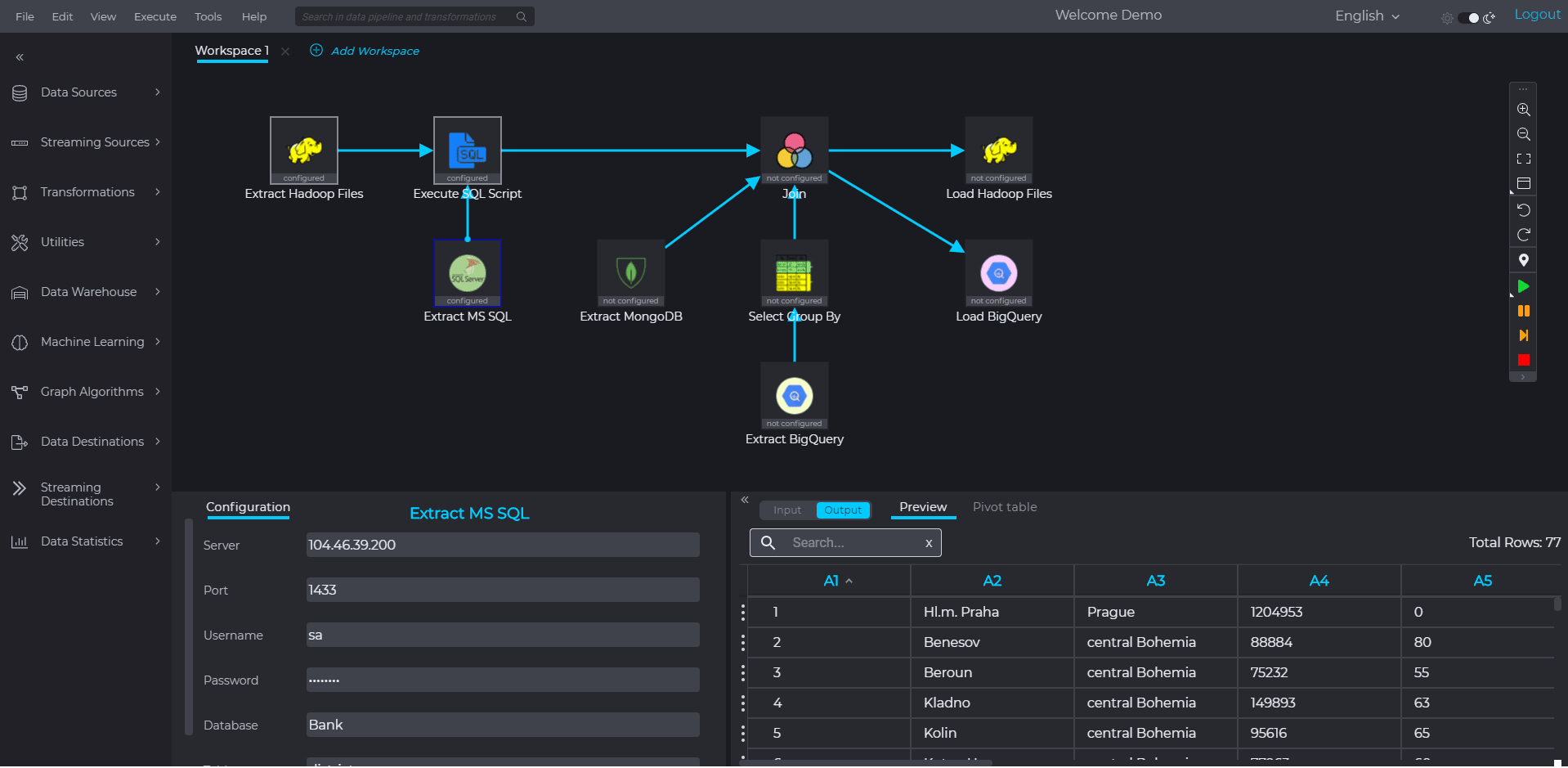
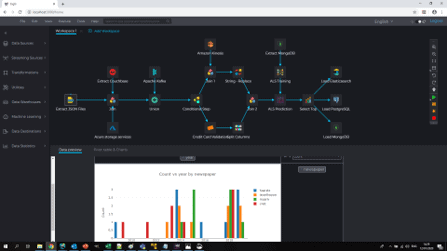
New data pipelines could be developed within hours, not days, and by the analysts themselves, with no need for lengthy R&D cycles.
As data pipelines are being run on the super-efficient Apache Spark distributed cluster, data pipelines could run up to 100x faster than on the legacy ETL. No more data pipelines that run for dull days, not finishing on time or need to be replaced with approximate calculation as the full calculation does not finish on time.
As BigBI is Spark native, its architecture fully duplicates Apache Spark architecture and feature set including: AI & ML algorithms & data preparation, graph algorithms, streaming data integration, efficient access to many types of semi-structured and unstructured data sets and much more.
BigBI is a cost-effective solution that can transform your legacy visual ETL environment into a modern data-processing beast while keeping data analysts’ self-supported, thus really democratizing big data analytics. If your current data-processing tools can no longer provide the insights that your organization needs to move forward, or your analysts needs to wait to lengthy programming cycles- the time is right to make the move to modern, easy-to-use, no-code tools that can handle all of your big-data processing and analytical needs.
To learn more about what BigBI can do for your business and to schedule a demo, contact BigBI today.